DynamoDBにおけるCRUD処理の注意点!
こんにちは、保険システム部の照屋です。
今回は、DynamoDBのCRUD処理をする際の注意点について紹介します。
DynamoDBをAPIで操作する際に、誤操作に繋がる点があったため、解決方法をまとめてみました。
DynamoDBとは
AWSの公式ドキュメントには
Amazon DynamoDB は、フルマネージドの NoSQL データベースサービスであり、高速で予測可能なパフォーマンスとシームレスな拡張性が特長です。
公式ドキュメント
DynamoDB では、一貫性のある高速パフォーマンスを維持しながら、スループットとストレージの要件を処理できるように、テーブルのデータとトラフィックが十分な数のサーバーに自動的に分散されます。また、すべてのデータをソリッドステートディスク (SSD) に保存し、AWS リージョン内の複数のアベイラビリティーゾーン間で自動的にレプリケートするため、組み込みの高い可用性とデータ堅牢性が実現します。
と記載されています。
まとめると、高速なパフォーマンスを行いながら、高い可用性と耐久性が維持できる、フルマネージド型のNoSQLデータベースサービスということです。
DynamoDBはキーバリューストア型であるという特徴があります。
キーバリューストア型は、キーとバリュー(値)という単純な構造であるため、高速なパフォーマンスが実現可能です。
ハッシュキーとソートキーからなる主キーが一意であれば、テーブルの項目は自由に設定することができます。
構成図
今回の構成図と処理の流れは以下のようになっています。
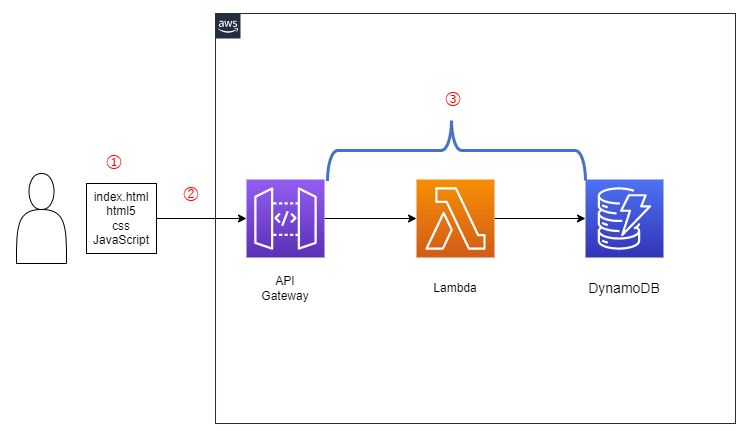
① アプリケーションの画面でCRUD処理をしたい情報を入力し、「処理実行」をクリックする
② JavaScriptのAjax処理でAPI Gatewayを呼び出す
③ API Gatewayに紐づけられたLambda関数で、CRUD処理を行う
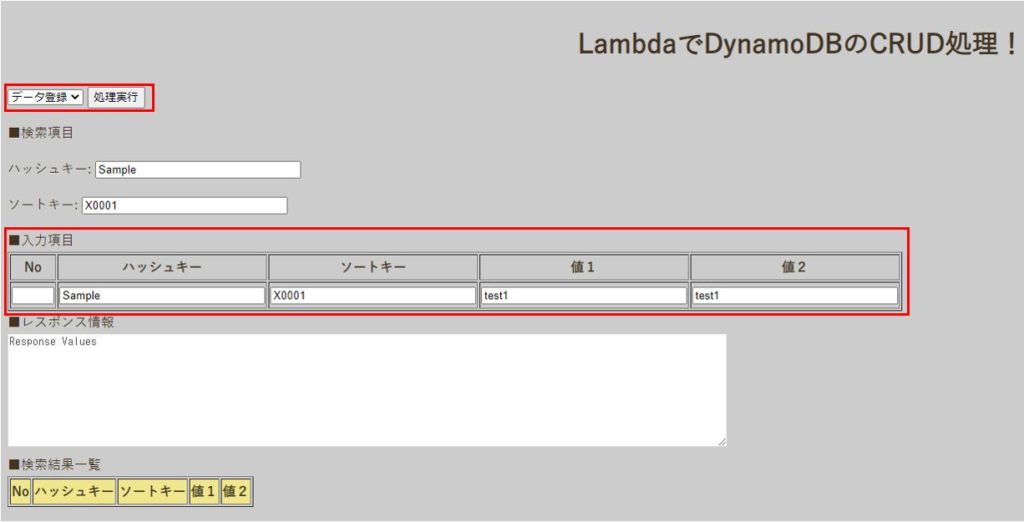
CRUD処理での注意点
LambdaでDynamoDBのCRUD処理を実装する際の注意点を紹介します。
LambdaはPythonで実装しており、PythonでAWSを操作するライブラリとしてBoto3を使用しています。
登録処理と更新処理が自動的に振り分けられる
Boto3でDynamoDBに対して登録処理と更新処理を行う場合は、put_itemというAPIを使用します。
put_itemは、ハッシュキーとソートキーからなる主キーが存在しない場合は登録処理を行い、すでに主キーが存在する場合は更新処理を行います。
自動的に振り分けられるのは便利である一方、登録処理のはずが更新処理を実行してしまうなどの誤操作が発生する可能性があります。
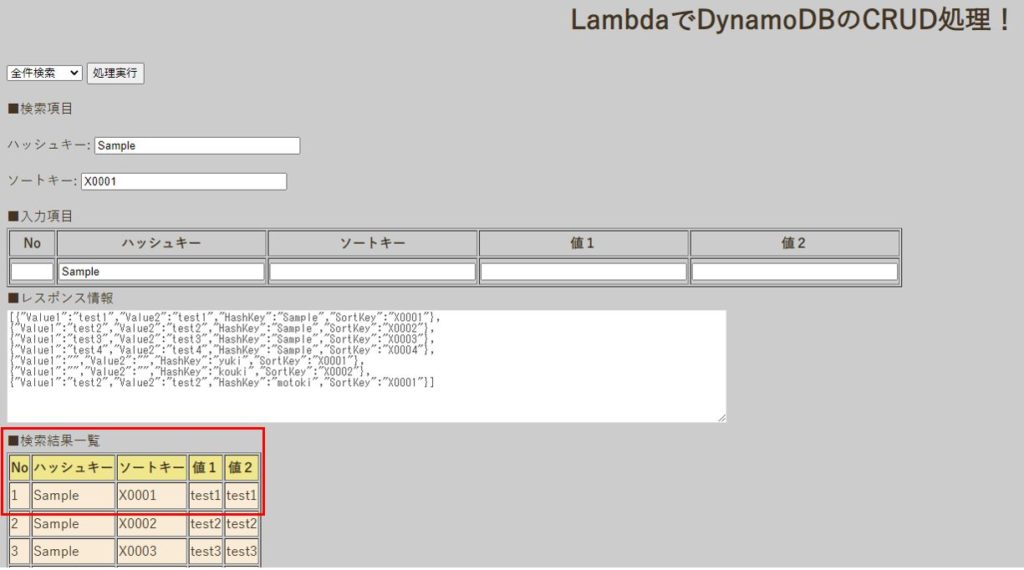
すでに[ハッシュキー:Sample、ソートキー:X0001]という主キーが存在した状態で、[ハッシュキー:Sample、ソートキー:X0001、値1:test2、値2:test2]というデータを入力し、登録処理を実行してみます。
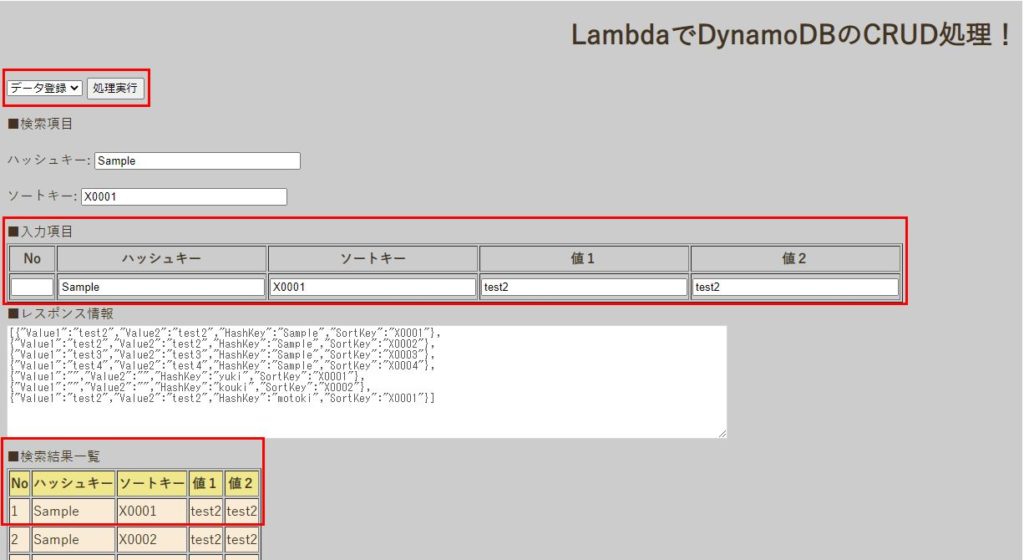
すでに登録されている主キーに対してput_itemを実行しているため、登録処理を行っているはずが、検索結果一覧を確認すると、[ハッシュキー:Sample、ソートキー:X0001]のデータが更新されてしまっています。
解決方法
誤操作を防止するために、以下のようなチェック関数を追加します。
- キー検索を行うoperation_query関数を実行する
- キー検索の結果をもとに、指定した主キーの存在チェックを行う
- レコード登録処理は、主キーが存在した場合に、戻り値としてエラーメッセージを返す処理を追加
- レコード更新処理は、主キーが存在しない場合に、戻り値としてエラーメッセージを返す処理を追加
修正したプログラムは以下のようになります。
Lambda Pythonプログラム
### チェック処理
def check_item(partitionKey, sortKey, OperationType):
items = CD.operation_query(partitionKey, sortKey)
# データ登録の場合
if OperationType == 'INSERT':
if items:
# エラーを返す
errorMessage = "{'ErrorMessage':'指定したキーのデータが存在します。'}"
return errorMessage
# データ更新の場合
if OperationType == 'UPDATE':
if not items:
# エラーを返す
errorMessage = "{'ErrorMessage':'指定したキーのデータが存在しません。'}"
return errorMessage修正後の動作を確認していきます。
修正前と同様に、[ハッシュキー:Sample、ソートキー:X0001]という主キーが存在した状態で、[ハッシュキー:Sample、ソートキー:X0001、値1:test2、値2:test2]というデータを入力し、登録処理を実行します。
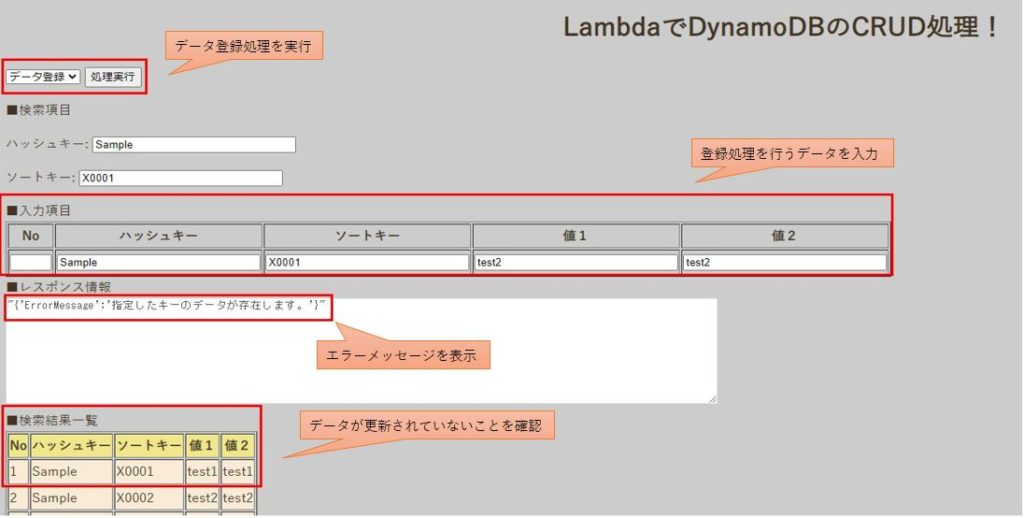
レスポンス情報に「指定したキーのデータが存在します。」というエラーメッセージが表示され、検索結果一覧も更新されていないことが確認できます。
続いて、更新処理の動作も確認していきます。
[ハッシュキー:Sample、ソートキー:X0001]という主キーが存在した状態で、[ハッシュキー:Sample2、ソートキー:X0002、値1:test2、値2:test2]というデータを入力して更新処理を実行します。
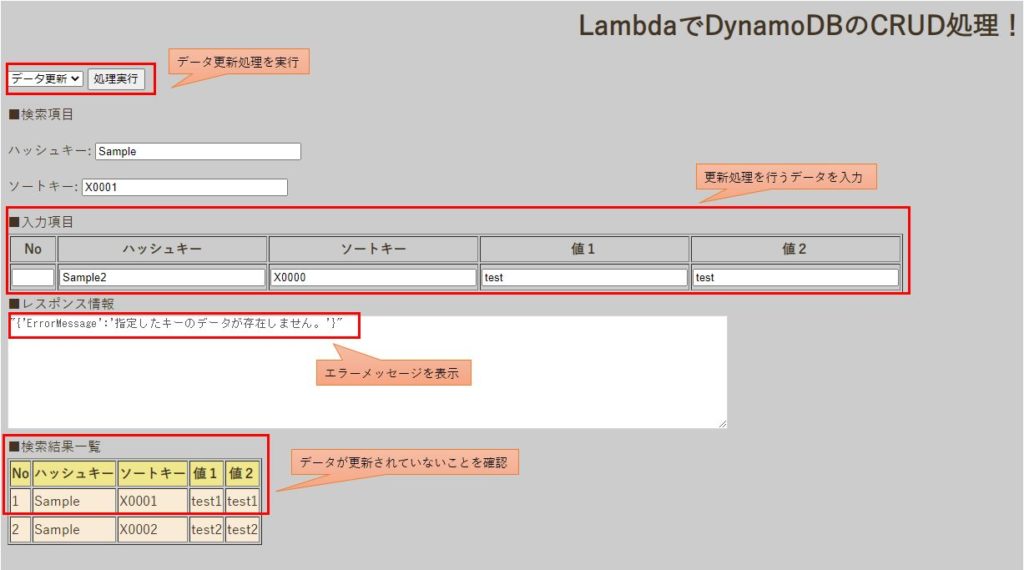
レスポンス情報に「指定したキーのデータが存在しません。」というエラーメッセージが表示され、検索結果一覧も更新されていないことが確認できます。
以上で、登録処理と更新処理での誤操作への対策は完了です!
補足
DynamoDBはデフォルトでは「結果整合性」であり、最新の書き込み結果が読み込み処理に反映されていない可能性があります。
そのため、チェック関数の存在チェックでの判定が上手くいかない恐れもあります。
確実に防止するには、全件検索を行うqueryのオプションでConsistentRead 属性を trueにすることで、「強力な整合性のある読み込み」へ変更する必要があります。
(この場合、読み込み時のコストは2倍になります)
さいごに
DynamoDBへの登録処理と更新処理の際の注意点を紹介しました。
今回紹介した方法の他に、put_item()にオプションとしてConditionExpression を指定という方法もあります。
ConditionExpression を指定する方法では、put_item()を実行した際に、既に主キーが存在した場合はエラーとすることができます。
今後もAPIでAWSを操作する上での注意点が見つかれば、紹介していきたいと思います!