Amazon QuickSight使ってみた!
こんにちは、保険システム部の照屋です。
現在、保険システム部ではAWSの活用について、検討や検証を行っています。
今回は利用の検討を行っているサービスの1つ「Amazon QuickSight」についてご紹介したいと思います。
Amazon QuickSight とは
Amazon QuickSightは、AWSが提供しているビジネスインテリジェンス (BI) サービスで、高速かつ簡単に情報を可視化することが可能になります。
Amazon QuickSightでは、S3やRDSなどのAWSサービス上にあるデータや、ローカルのCSVファイルなどを使用して分析を行うことができます。
さらに、機械学習(ML)機能を活用した、異常検出や数値の予測など、より高度な分析を簡単に行うこともできます。
SPICEとは
QuickSightでは、CSVファイルやTSVファイルなどのデータソースを「SPICE」というデータ領域に取り込むことで分析が可能になります。
SPICEとは
- Super-fast (超高速)
- Parallel (並列)
- In-memory Calculation Engine (インメモリ計算エンジン)
の頭文字を取ったものです。
SPICEは、QuickSightの専用エンジンで、SPICEにデータソースをアップロードすると、すぐに情報の分析や可視化を行えるようになります。
SPICEでは、分析やビジュアルを変更・更新するたびに、データを再取得する必要が無く、効率的に分析を行うことが可能です。
SPICEの構築手順
今回は、下記の2パターンでSPICEの構築を行っていきます。
- ローカルのCSVファイルをアップロード
- S3上のファイルをアップロード
ローカルのCSVファイルをアップロード
1つ目のインポート作業として、ローカルにあるAssign.csvとPatient-Info.csvという2つのCSVファイルをアップロードしていきます。
まずマネジメントコンソールから、QuickSightにアクセスし、「新しい分析」をクリックします。
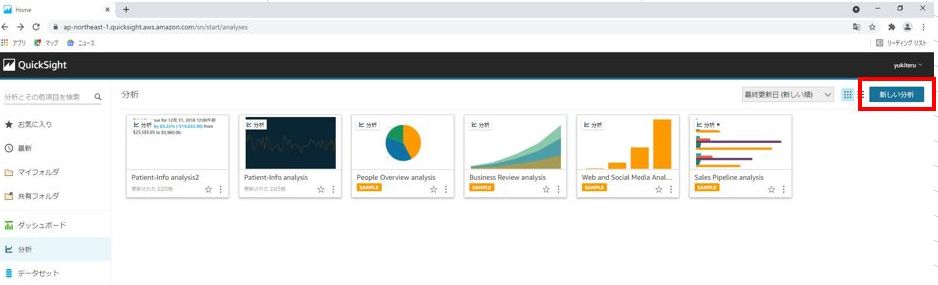
データセットの選択画面で、「新しいデータセット」をクリックします。
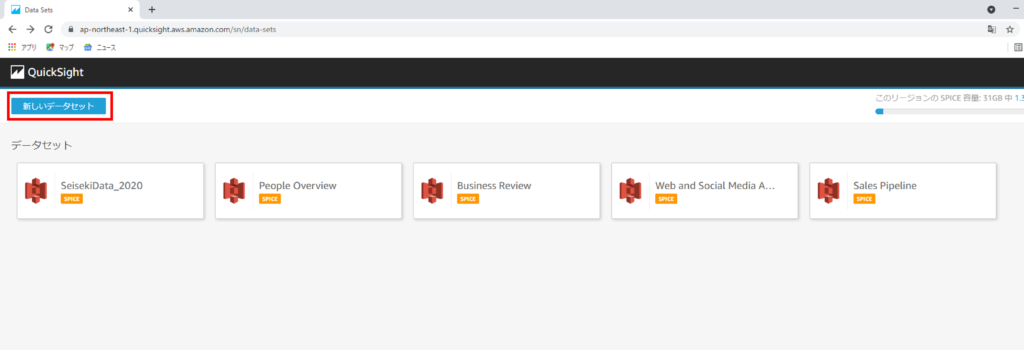
手順通りに操作すると、アップロード方法を選択する画面に遷移します。
ローカルファイルからアップロードする方法や、AWSサービスからアップロードする方法を選択できます。
ここでは、ローカルのCSVファイルをアップロードするため、「ファイルのアップロード」を選択します。
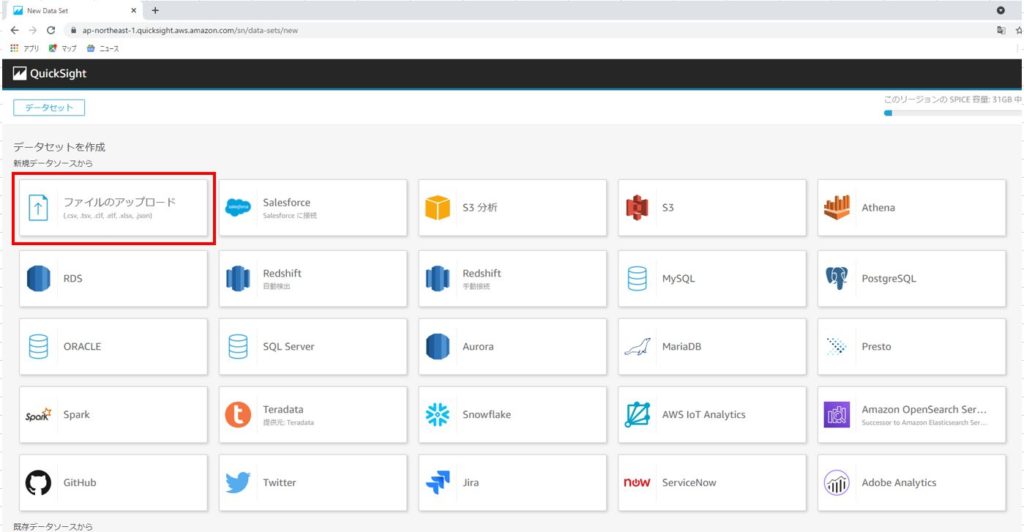
ファイル選択のダイアログで、アップロードしたいファイルを選択します。
そうすると、ファイルのアップロード設定の確認画面が表示されます。
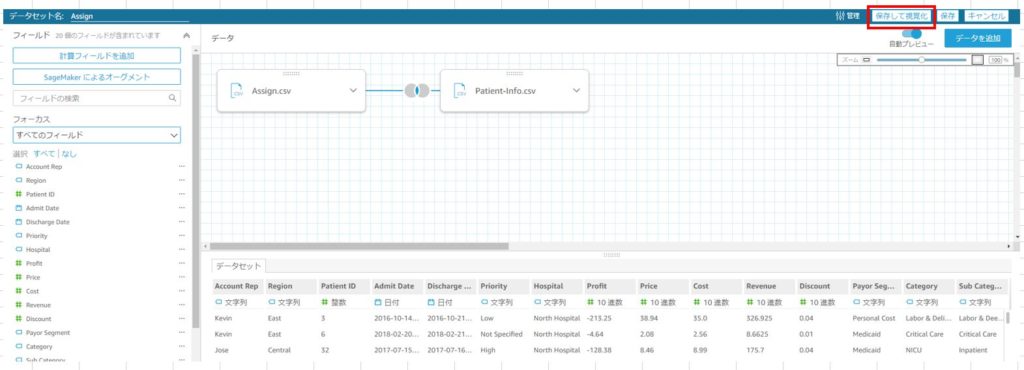
1つ目のインポート作業では、2つのデータソースを結合(Join)するため、「設定の編集とデータの準備」をクリックします。
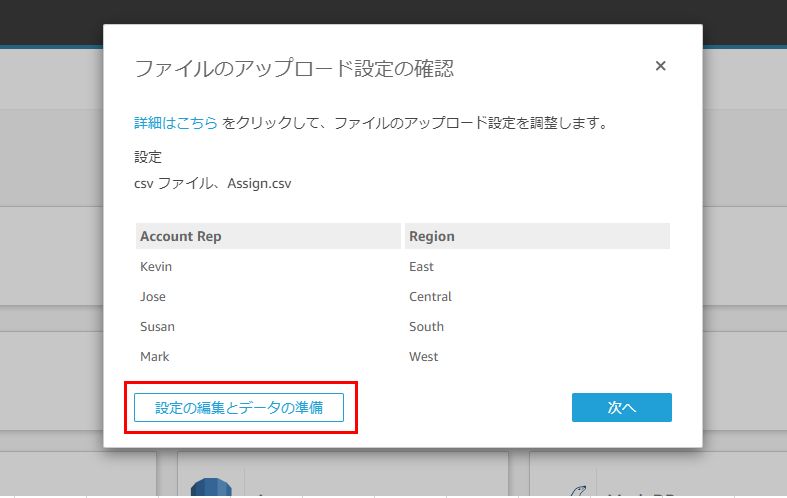
以下の画面では、分析の準備として、フィールド(列)の名前を変更したり、不要なフィールド(列)を隠すことも可能です。
今回のように、他のデータソースを結合する際は、右上の「データを追加」をクリックし、表示されるダイアログで「ファイルのアップロード」を選択します。
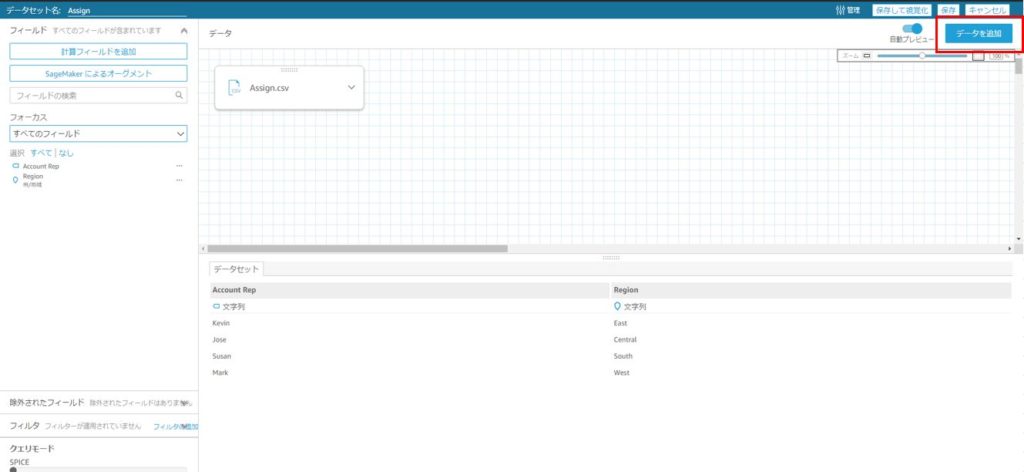
アップロードしたいファイルを選択し、ファイルのアップロード設定の確認画面が表示されたら、「次へ」をクリックします。
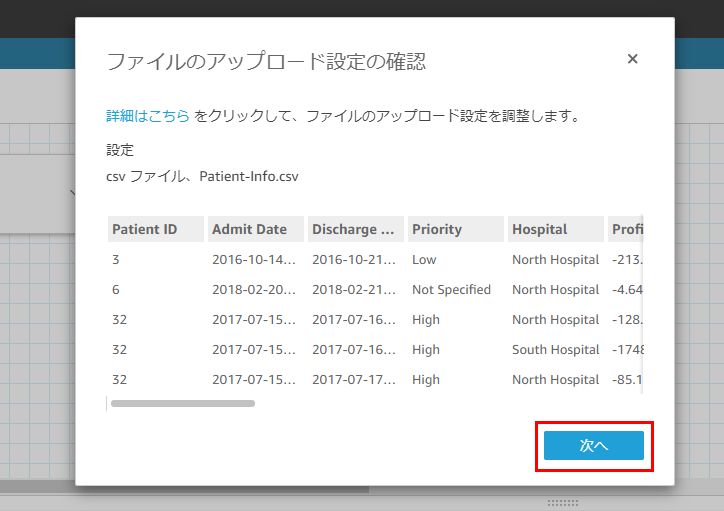
以下の画面から、2つのデータソースの結合を行っていきます。
画面左上の赤い円のようなアイコンをクリックし、画面下に表示される結合設定で結合するフィールドを選択します。
今回はRegion フィールドで結合するため、両方ともRegion フィールドを選択します。
結合タイプは内部結合(Inner)を選択し、「適用」をクリックします。
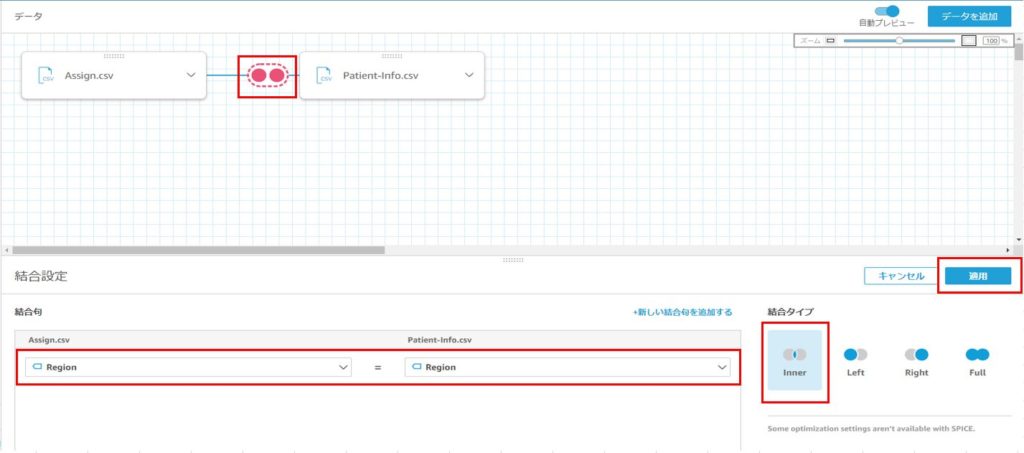
結合が上手くいくと、画面左側に2つのデータソースのフィールドが表示されるようになります。
Regionフィールドは、両方のデータソースに存在し、画面にも2つ表示されているため1つを非表示にします。
フィールド名右側の「…」をクリックし、「フィールドを除外」を選択することで非表示にすることができます。
画面右上の「保存して視覚化」をクリックし、”インポートの完了”のダイアログで「100%が成功しました」と表示されたら、インポート完了です。

S3上のファイルをアップロード
続いて、2つ目のインポート作業として、S3上にあるCSVファイルをアップロードしていきます。
先ほどと同様に、マネジメントコンソールから、QuickSightにアクセスし、「新しい分析」をクリックします。
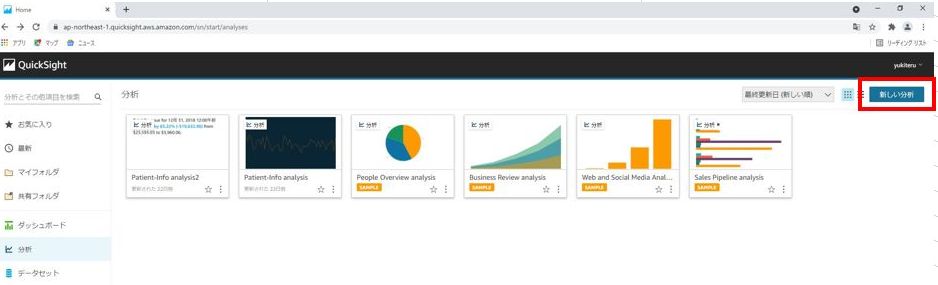
次のデータセットの選択画面で、「新しいデータセット」をクリックします。
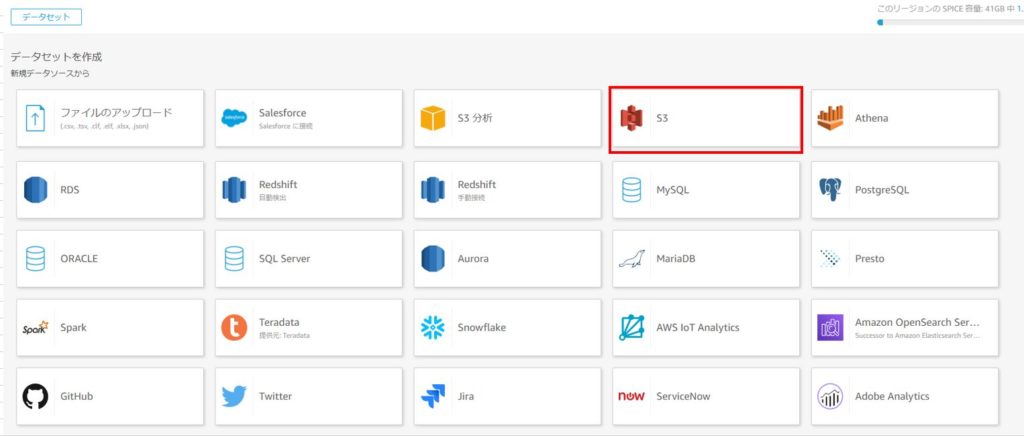
アップロード方法を選択する画面で、S3をクリックします。
S3を選択すると、以下のようなダイアログが表示されます。
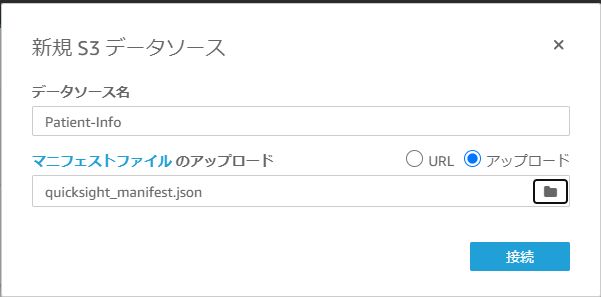
データソース名に、S3にある、今回アップロードしたいファイル名を入力します。
マニフェストファイルとは、利用するデータファイルの形式や保管先を定義しているファイルで、
以下のようなjsonファイルです。
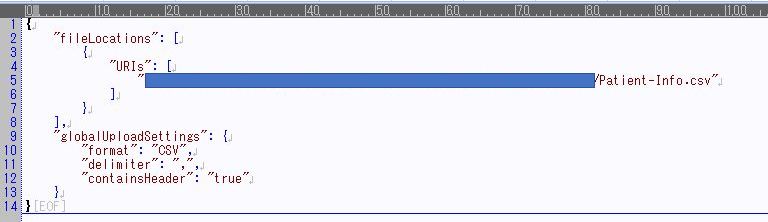
fileLocations > URIs には、S3にアップロードしたファイルの オブジェクトURL を指定します。
カンマ区切りで複数のファイルを指定することも可能です。
globalUploadSettings には、ファイル形式の定義を記載します。
- format : ファイルの拡張子を指定(CSV、TSVなど)
- delimiter : ファイルの区切り文字を指定(CSVなら"," TSVなら"\t"など)
- containsHeader : ファイルにヘッダーを含むかどうか(含むならtrueを設定)
- textqualifier : 文字列の項目を囲む際の記号を指定(今回、文字列の項目を囲む記号は無いので未設定)
データソース名を入力し、マニフェストファイルを指定したら、「接続」をクリックします。
クリックすると、下図の画面に遷移します。
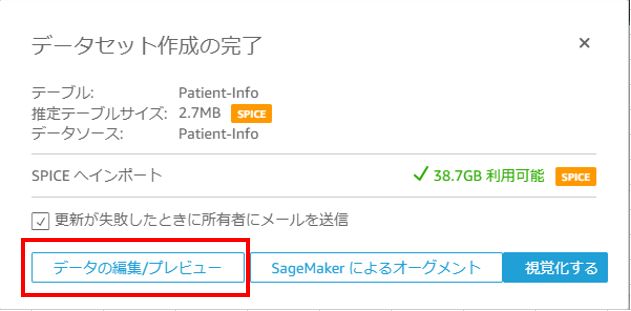
「視覚化する」をクリックすると、そのままデータ分析の画面に遷移することができます。
しかし、データをインポートする際にエラーが起き、取り込めなかったデータがある場合、そのデータが欠落した状態で分析へ進むこととなります。
そのため、「データの編集/プレビュー」をクリックし、以下の画面でインポートでのエラーの有無を確認することをおすすめします。
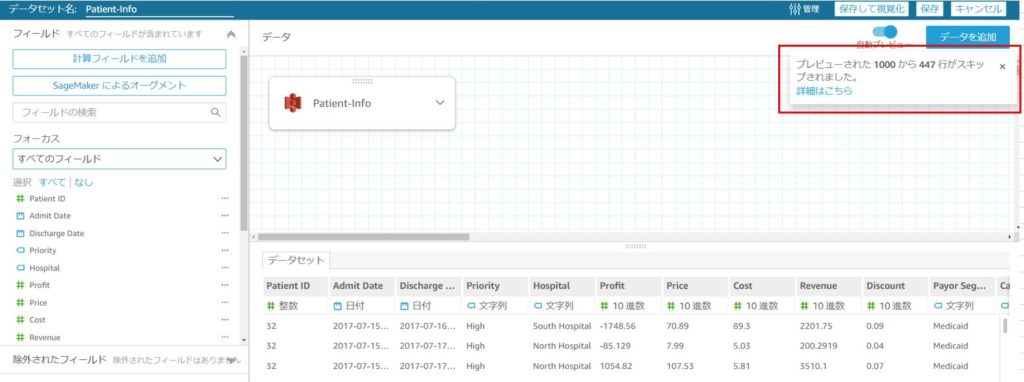
画面右上に「プレビューされた1000から447行がスキップされました。」というメッセージが表示されています。
これはインポートでエラーとなったために取り込めなかったデータがある、ということを示します。
先ほどの画面で、「視覚化する」をクリックしてしまうと、このメッセージが確認できず、そのままデータが欠落してしまうため注意しましょう。
インポートでエラーとなるのは、以下のような場合です。
| エラー内容 | エラー詳細 | 対処法 |
|---|---|---|
| フォーマットの違い | 日付型の項目に、「yyyy/MM/dd」と「yyyy/MM/dd HH:mm:ss」のような異なるフォーマットの日付が入っている | フォーマットをどちらかに統一し、ファイルのアップロードからやり直す |
| 数値項目に数字以外が含まれている | 数値(整数)型と認識された項目に、アルファベットや記号が入っている | データタイプを「文字列」に変更する |
誤ったデータタイプが設定されている場合、手動で修正が必要です。
変更したい項目の右側の「…」をクリックし、データタイプの変更から文字列を選択します。
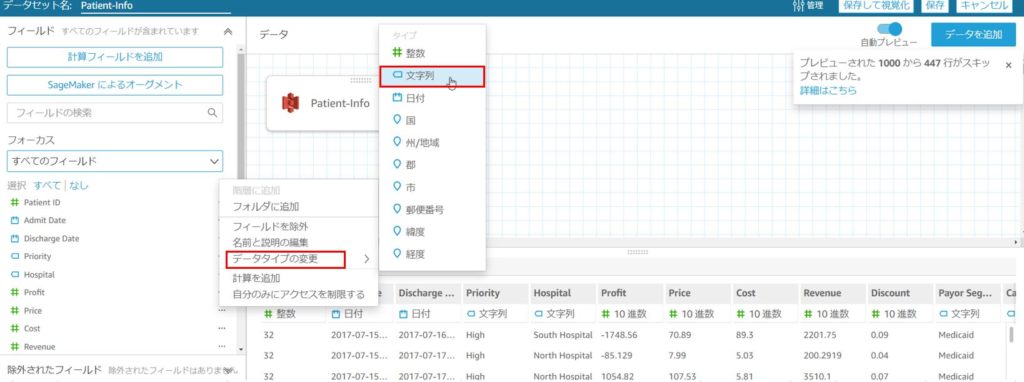
この作業を項目ごとに行います。
主に確認するのは、「日付型」と「整数」で設定されている項目です。
完了したら、画面右上の「保存」をクリックします。
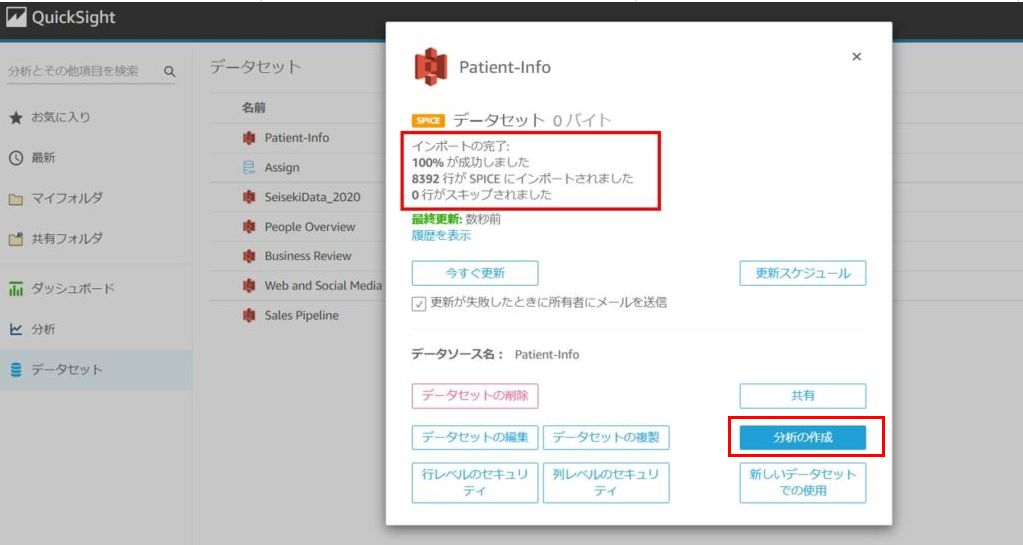
保存が完了したら、データセットの一覧画面に遷移します。
そこで今回作成したデータセット名をクリックして、ダイアログに「100%が成功しました」と表示されていることが確認できたら、アップロード完了です。
実際に分析を行う際は、ダイアログの「分析の作成」をクリックします。
すると、グラフを作成するダッシュボードの画面へ遷移します。
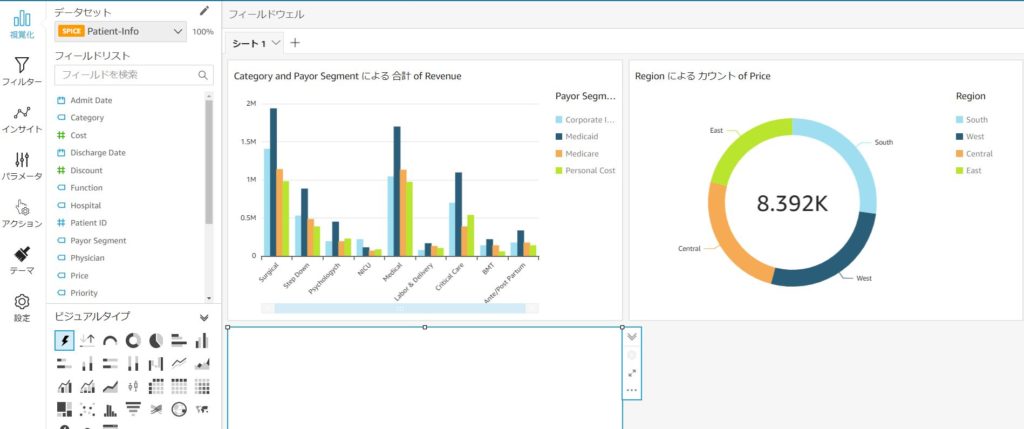
画面左下のビジュアルタイプでグラフの種類を選択後、画面左のフィールドリストから分析に使用するフィールドを選択することで、データをグラフで可視化できるようになります。
上図のようにグラフが作成できたら、実際に分析を開始することができます。
さいごに
今回は、Amazon QuickSightの専用エンジンである、SPICEの構築を行いました。
ローカルからのCSVファイルのアップロードと、S3からのアップロードによって構築することができました。
誤ったデータタイプが設定されて、インポートでエラーが発生した際の修正は手作業なので、その点は多少手間がかかりました。しかし、その他は特に複雑な操作はなく、スムーズに構築を進めることができました。
S3以外にも、AthenaやRedShiftなどのAWSサービスとも連携できるようなので、試してみたいと思います!