サーバレスで画像のモザイク処理を作ってみた②
こんにちは、宮内です。
前回はモザイク処理を実装するための下準備として、Lambda Layerの設定まで行いました。
今回はいよいよ、本題のモザイク処理の実装を説明します!
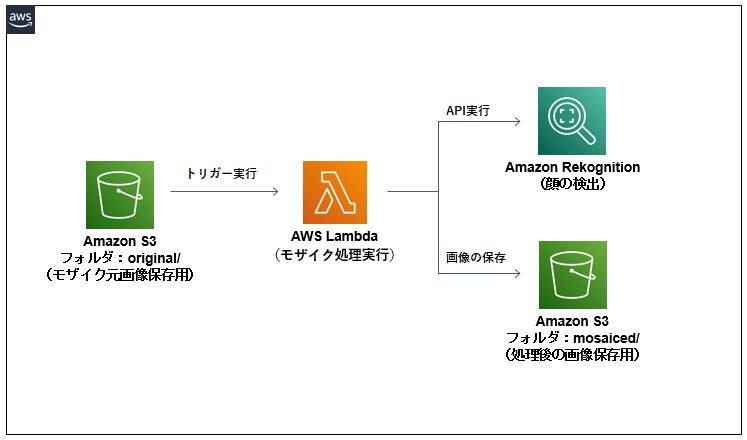
システム構成図
S3への画像ファイルのアップロードをトリガーとして、Lambdaを実行するシンプルな構成です。
S3に関してはモザイク元画像保存用、モザイク処理後画像保存用の2つありますが、バケットは同じで、フォルダを分ける設計にしています。
使用するサービスについて
各種サービスの概要と用途について説明します。
- Amazon S3(Simple Storage Service)
AWSのオブジェクトストレージサービス。
画像ファイルを保存するストレージとして使用します。
- AWS Lambda
AWSのサーバレスコンピューティングサービス。
モザイク処理のプログラムコードをPython3.8で実装して使用します。
★前回、Pillowのレイヤーを設定したLambdaを使用しましょう!
- Amazon Rekognition(Image)
AWSの画像分析サービス。
画像内の顔検出を行う「DetectFaces」というAPIを使用します。
モザイク処理の実装
Lambdaに実装するプログラムコードの説明をします。
# 1.ライブラリのインポート
from PIL import Image
import boto3
from io import BytesIO
def lambda_handler(event, context):
# 2.バケット名とファイル名を取得
bucket_name = event['Records'][0]['s3']['bucket']['name']
file_name = event['Records'][0]['s3']['object']['key']
# 3.Lambdaと他のAWSサービス(Rekognition,S3)を連携
rekognition_client = boto3.client('rekognition')
s3_resource = boto3.resource('s3')
bucket = s3_resource.Bucket(bucket_name)
# 4.変数、定数定義
list_boundingbox = []
MOSAIC_IMAGE_PREFIX = 'mosaiced/mos_'
try:
# 5.RekognitionのAPI実行
response = rekognition_client.detect_faces(Image={'S3Object':
{'Bucket':bucket_name,
'Name':file_name}
},
Attributes=['DEFAULT'])
# 画像内に顔が写っていない場合
if len(response['FaceDetails']) == 0:
# 処理結果
result = '画像ファイル内に顔が検出されませんでした。'
# 画像内に顔が写っている場合
else:
# 6.顔の位置情報を取得
for faceDetail in response['FaceDetails']:
boundingbox = []
boundingbox.append(faceDetail['BoundingBox']['Left'])
boundingbox.append(faceDetail['BoundingBox']['Top'])
boundingbox.append(faceDetail['BoundingBox']['Width'])
boundingbox.append(faceDetail['BoundingBox']['Height'])
list_boundingbox.append(boundingbox)
# 7.画像データ取得
response = bucket.Object(file_name).get()
body = response['Body'].read()
im = Image.open(BytesIO(body))
im_width = im.width
im_height = im.height
# 8.画像のモザイク処理
for boundingBox in list_boundingbox:
x1 = (float)(boundingBox[0]*im_width)
y1 = (float)(boundingBox[1]*im_height)
x2 = x1 + (float)(boundingBox[2]*im_width)
y2 = y1 + (float)(boundingBox[3]*im_height)
face = im.crop((x1, y1, x2, y2))
mos_img = face.resize([x // 16 for x in face.size]).resize(face.size)
im.paste(mos_img, (int(x1), int(y1)))
# 9.メモリ上でモザイク処理後の画像を保存
bytesIo = BytesIO()
im.save(bytesIo, format=im.format)
bytesIo.seek(0)
# 10.モザイク処理後の画像をS3にアップロード
idx = file_name.find('/')
file_name = file_name[idx+1:]
processed_file_name = MOSAIC_IMAGE_PREFIX + file_name
bucket.put_object(
Body = bytesIo,
Key = processed_file_name,
ContentType = 'image/jpeg'
)
result = 'モザイク処理実行! 保存ファイル名:' + processed_file_name'
except Exception as e:
print(e)
# 11.処理結果を表示、返却
print(result)
return(result)
それでは、実装の主要な部分について細かく見ていきましょう!
ライブラリのインポート
from PIL import Image
import boto3
from io import BytesIO
今回使用するライブラリは以下の3つです。
- PIL.Image:画像データを扱うためのライブラリ。モザイク処理のかなめとなる。
- boto3:PythonでAWSのリソースを操作するためのライブラリ。LambdaでPythonを使うなら欠かせない。
- io.BytesIO:メモリ上でバイナリデータを操作するためのライブラリ。画像をバイナリデータとして処理するために使用する。
RekognitionのAPI実行
response = rekognition_client.detect_faces(Image={'S3Object':
{'Bucket':bucket_name,
'Name':file_name}
},
Attributes=['DEFAULT'])
画像内の顔を検出するため、RekognitionのAPI「DetectFaces」を使用します。
リクエストパラメータで設定するのは、ImageとAttributesの2つになります。
- Image:分析を行う画像ファイルを設定する。今回はS3にアップロードされた画像ファイルを指定する。
- Attributes:ALL、またはDEFAULTを設定する。ALLは取得可能な全情報、DEFAULTは一部情報だけを取得する。
AttibutesでALLを指定すると、年齢や性別、表情といった詳細な分析結果も取得できます。
モザイク処理で使用する情報は、DEFAULT指定でも取得可能なので、今回はDEFAULTを指定しています。
「DetectFaces」の詳細については、AWS公式のAPIリファレンスをご覧ください。
画像内に顔が写っていない場合
if len(response['FaceDetails']) == 0:
# 処理結果
result = '画像ファイル内に顔が検出されませんでした。'
画像の顔情報は FaceDetails というリストで返却されます。
顔が検出されなかった場合はリストの長さが0になるため、リストの長さが0の場合はモザイク処理を実行しないようにしています。
ちなみに複数人の顔が写っている場合は、リストの要素が複数個設定されます。
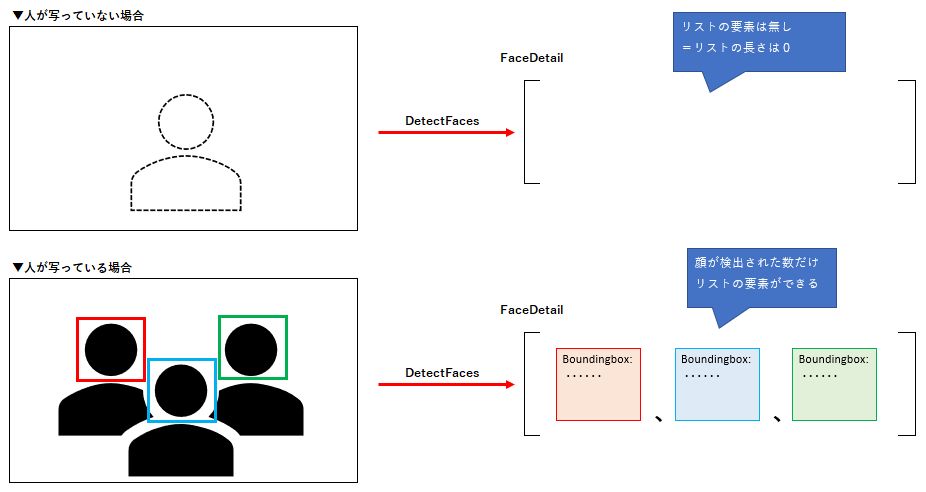
以降の処理は顔が写っている場合の処理です。
顔の位置情報を取得
for faceDetail in response['FaceDetails']:
boundingbox = []
boundingbox.append(faceDetail['BoundingBox']['Left'])
boundingbox.append(faceDetail['BoundingBox']['Top'])
boundingbox.append(faceDetail['BoundingBox']['Width'])
boundingbox.append(faceDetail['BoundingBox']['Height'])
list_boundingbox.append(boundingbox)
複数人写っている場合を考慮し、顔の位置情報はfor文でまとめて取得します。
ここで利用するのが、レスポンスに含まれている BoundingBox の値です。
BoundingBoxとは
「境界ボックス」と呼ばれるもので、顔を囲む四角形の枠のことを指します。
BoundingBoxにはパラメータが4つあります。
- Left:画像全体の幅の比率としての、BoundingBoxの左端座標
- Top:画像全体の高さの比率としての、BoundingBoxの上端座標
- Width:画像全体の幅の比率としての、BoundingBoxの幅
- Height:画像全体の高さの比率としての、BoundingBoxの高さ
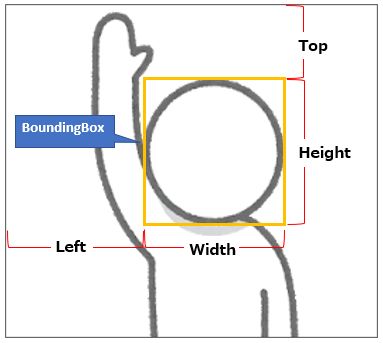
注意点としては、それぞれの値は画像の幅や高さ(ピクセル)に対する「比率(0~1の値)」であるという点です。
例えば、顔の縦の大きさ(Height)が画像の高さに対してちょうど半分だった場合、Heightには「0.5」という値が設定されます。
モザイク処理ではピクセル値を使うため、BoundingBoxの値をそのまま利用することはできません。
そこで、比率をピクセル値へ変換するには、画像の幅と高さのピクセル値を取得する必要があります。
画像データ取得
response = bucket.Object(file_name).get()
body = response['Body'].read()
im = Image.open(BytesIO(body))
im_width = im.width
im_height = im.height
まずはバケットのリソースを利用して、S3から画像データを取得します。
取得した画像データはPillowとBytesIOを利用してバイト列に変換し、画像の幅と高さを取得します。
これでモザイク処理を実行する準備ができました。
画像のモザイク処理
ここは少し数学チックな話になります。
モザイク範囲の特定
まずはモザイクをかける範囲を特定します。
求めたいのはBoundingBoxの左上の座標(x1、y1)と、右下の座標(x2、y2)です。
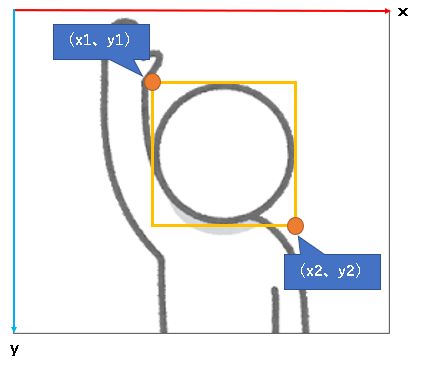
左上の座標(x1、y1)の求め方は簡単で、
左上のx座標(x1) =(画像の幅)×(BoundingBoxの左端座標の比率:Left)左上のy座標(y1) =(画像の高さ)×(BoundingBoxの上端座標の比率:Top)
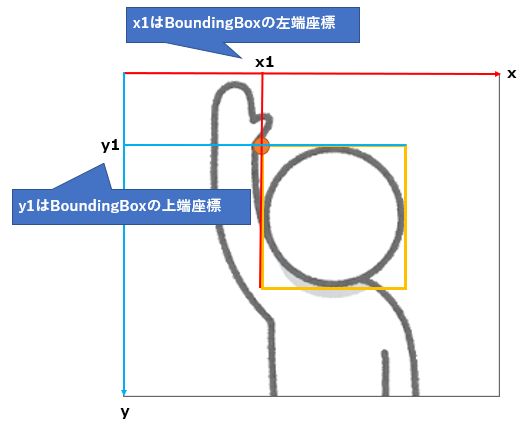
で求められるので、以下の実装となっています。
x1 = (float)(boundingBox[0]*im_width)
y1 = (float)(boundingBox[1]*im_height)
一方、右下の座標(x2、y2)は、左上の座標(x1、y1)を利用して求められます。
右下のx座標(x2) =(左上のx座標(x1))+(BoundingBoxの幅)
=(左上のx座標(x1))+{(画像の幅)×(BoundingBoxの幅の比率:Width)}右下のx座標(y2) =(左上のy座標(y1))+(BoundingBoxの高さ)
=(左上のy座標(y1))+{(画像の高さ)×(BoundingBoxの高さの比率:Height)}
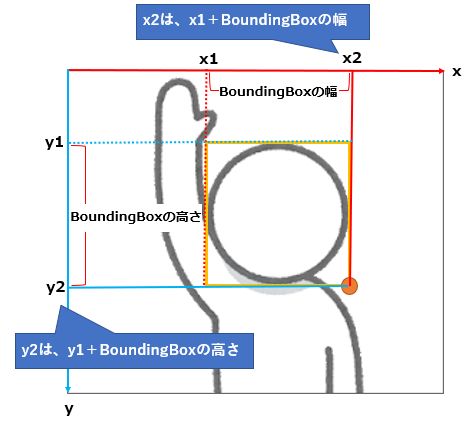
実装は以下の通りです。
x2 = x1 + (float)(boundingBox[2]*im_width)
y2 = y1 + (float)(boundingBox[3]*im_height)
同じような説明は、AWS公式のデベロッパーガイドにもありますので、是非こちらもご覧ください。
モザイク処理の実装
face = im.crop((x1, y1, x2, y2))
mos_img = face.resize([x // 16 for x in face.size]).resize(face.size)
im.paste(mos_img, (int(x1), int(y1)))
モザイク処理の実装ですが、実はPillowにモザイク処理を行なう関数は定義されていません。
そこで、複数の関数を呼び出すことで、疑似的なモザイク処理を作ります。
crop関数により、モザイクする範囲を切り取る。resize関数により、切り取った画像を縮小し、元のサイズに拡大する。(画像を粗くする)paste関数により、切り取った範囲を元の画像に貼り付ける。
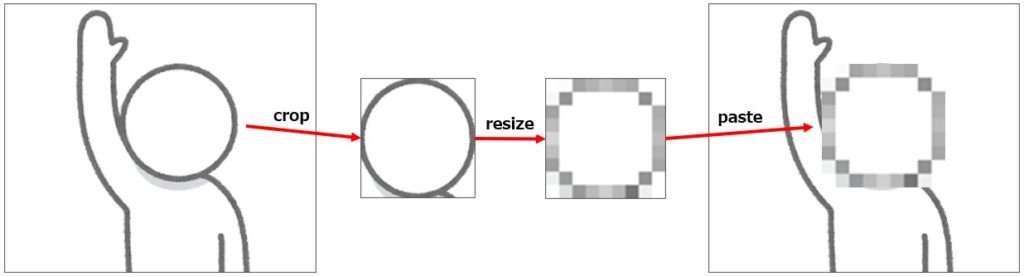
メモリ上でモザイク処理後の画像を保存
bytesIo = BytesIO()
im.save(bytesIo, format=im.format)
bytesIo.seek(0)
今回はサーバレスでの実装なので、BytesIOを利用してメモリ上で画像を保存します。
seek関数はバイト列の読み始める位置(ポインタ)を先頭に変更するおまじないで、画像を正常に保存するために必要となります。忘れないようにしましょう。
モザイク処理後の画像をS3にアップロード
idx = file_name.find('/')
file_name = file_name[idx+1:]
processed_file_name = MOSAIC_IMAGE_PREFIX + file_name
bucket.put_object(
Body = bytesIo,
Key = processed_file_name,
ContentType = 'image/jpeg'
)
最後に、メモリ上で保存した画像をS3へアップロードします。
1~2行目では、ファイル名に付いている「original/」という接頭辞を外して、ファイル名のみを取得しています。
この中で忘れてはいけないのが、「ContentType = 'image/jpeg’」の設定です。
この設定を忘れてしまうと、アップロードしたファイルが「applicaton/octet-stream」で設定されてしまい、バイナリファイルの扱いとなってしまうため、ファイルを開こうとする度にダウンロードが発生します。
S3にファイルをアップロードする場合は、必ずContentTypeを設定するようにしましょう!
Lambdaのトリガー設定
最後にLambdaのトリガー設定を行います。
Lambdaの編集画面の上部にある 関数の概要 の「トリガーを追加」をクリックします。
トリガーの設定画面が開きますので、必要な項目を入力します。
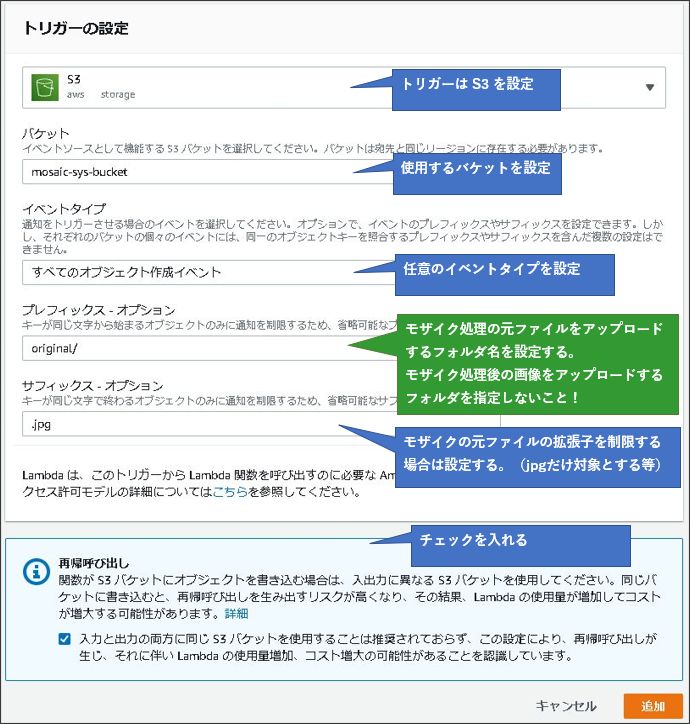
ここで注意すべきなのが「プレフィックス-オプション」の項目です。
今回のLambdaの仕様として、S3への画像アップロードをトリガーに処理を行ない、モザイク処理後の画像をS3にアップロードしています。
この時、モザイク処理後のファイルを「プレフィックス-オプション」で設定したフォルダに保存すると、モザイクをかけた画像をトリガーにLambdaが実行されるため、処理がループする(再帰的にLambdaが実行される)恐れがあります。
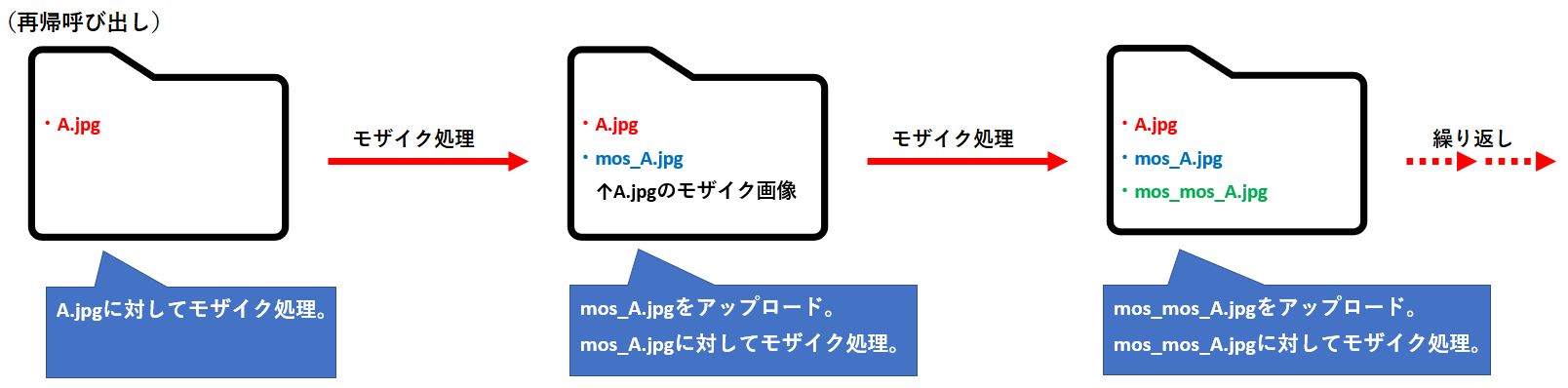
再帰呼び出しを避けるために、
「プレフィックス-オプション」で設定したフォルダ(処理のトリガーとなる画像ファイルをアップロードするフォルダ)と、モザイク処理後の画像をアップロードするフォルダが異なること
は必ず確認しておきましょう!
今回はバケットを共有しているため注意が必要ですが、使用するバケットを別々にしていれば心配は無いですね。問題が無ければ追加をクリックし、トリガーを設定します。
実際に動かしてみる
それでは実際にモザイク処理を実行してみましょう!
こちらの集合写真を使って検証します。
https://www.photo-ac.com/main/detail/315222?title=%E9%9D%92%E7%A9%BA%E3%81%AE%E4%B8%8B%E3%80%81%E3%82%B9%E3%83%9E%E3%83%9B%E3%81%A7%E8%A8%98%E5%BF%B5%E5%86%99%E7%9C%9F7
引用元:photoAC
トリガーに設定したフォルダに画像をアップロードします。
CloudWatchを確認すると、モザイク処理実行のログが出力されています!
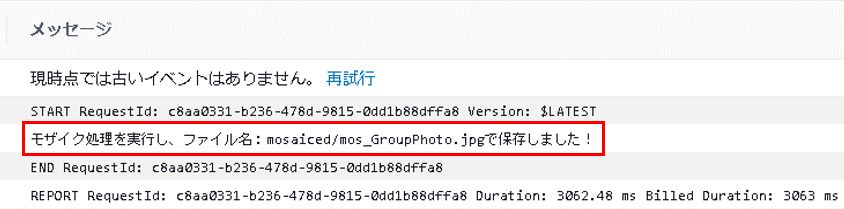
ログ出力の通り、mosaicedフォルダに画像がアップロードされていました。
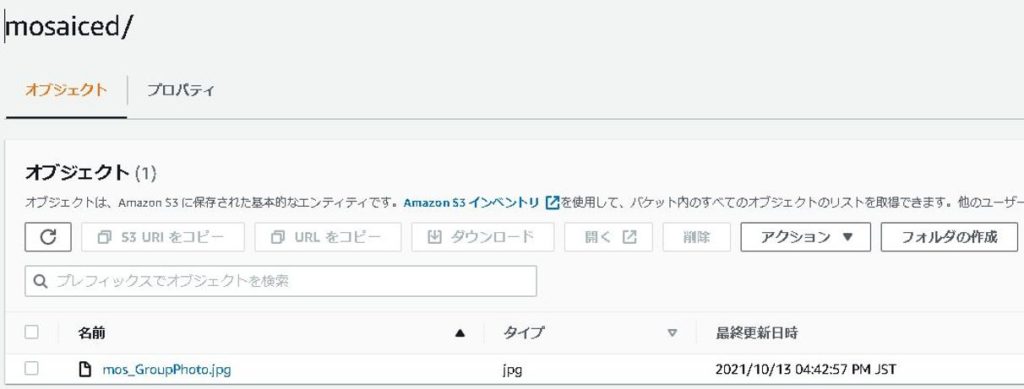
画像を開いてみると…

顔の部分だけモザイクがかかっていました(^^)v
BoundingBoxの範囲に対してモザイク処理をしているので、モザイクの形が四角形になっていますね。
次に、顔が写っていない画像の場合も確認してみましょう。
http://www.irasutoya.com/2016/01/blog-post_23.html

トリガーに設定したフォルダに画像をアップロードします。
CloudWatchを確認すると、顔が検出されなかったとログが出ており、mosaicedフォルダにも画像はアップロードされていませんでした。
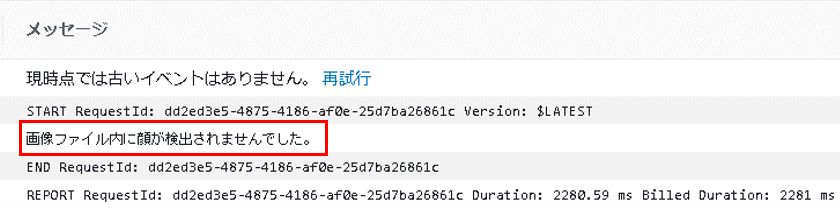
想定通りに処理できていますね!
追加検証:縮小の倍率(モザイク度)を変えてみる
モザイク処理で画像の縮小を行っていますが、今回の実装では縮小の倍率(以下、モザイク度)を16倍に設定しています。
↓このプログラムの「16」がモザイク度ですmos_img = face.resize([x // 16 for x in face.size]).resize(face.size)
モザイク度に設定する値によって処理結果がどう変わるのか確認してみました。

よく見るモザイク画像はモザイク度4、8の辺りでしょうか。
モザイク度32だと肌色一色になってしまい、モザイクとは程遠いですね(笑)
また、モザイク処理をかけた画像に対して、再びモザイク処理ができるかを確認したところ、モザイク度が4、8の場合は再処理できることが分かりました。
画像が多少粗くても、Rekognitionでは顔と認識できるようです。Rekognitionの顔認識の精度は高いですね!
さいごに
今回はサーバレスで画像のモザイク処理を実装しました。
Lambda Layerといった拡張機能を利用し、シンプルな構成にできたと思います。
Rekognitionを利用して画像の編集を行いましたが、Rekognitionのコレクション機能を利用すると、特定の人はモザイクをかけないといった実装もできそうなので、試してみたいと思います!