Amazon Athena+AWS GlueでS3上のデータを分析してみた
こんにちは、保険システム部の照屋です。
今回は、Amazon AthenaとAWS Glueを使用して、S3上にあるCSVデータに対してクエリを実行してみます。
さらに、AthenaのデータをQuickSightで分析できるように、AthenaとQuickSightの連携も行います。
Amazon Athenaとは
Amazon Athenaは、標準SQLを使用してS3内のデータを分析することができるサービスです。
Amazon Athenaには、以下の特徴があります。
1. サーバレスである
Athenaはサーバレスであるため、サーバインスタンスを立てたり、管理する必要がありません。
S3にデータを保存し、テーブルを定義するだけでSQLクエリを実行することが可能です。
2. クエリごとに料金が発生
Athenaでは、クエリでスキャンされるデータの量に対して料金が発生します。
そのため、データの圧縮、分割、列形式への変換を行うことで、コストを削減することができます。
3.高速である
クエリが自動的に並列で実行されるため、大規模なデータに対しても数秒で結果を得ることが可能です。
AWS Glueとは
AWS Glue は、完全マネージド型 ETL (Extract/Transform/Load、抽出/変換/ロード) サービスです。
Glueには、AWS Glue Data Catalogという、メタデータの保存や共有ができるメタデータストアがあります。
AthenaとGlueの関係性について
Athenaで、S3にあるファイルを分析するには、AWS Glue Data Catalogに対してクエリを実行します。
そのため、初めにGlueの構築を行い、その後にAthenaの構築を行います。
Glueの構築
今回は、Glueのクローラ機能を使用して構築を行います。
クローラとは、分析に使用したいファイルからデータを抽出し、AWS Glue Data Catalogにテーブル形式でメタデータを保存するプログラムです。
クローラの作成
今回は、全国の男女別人口に関するCSVファイルを使用します。
Glueのコンソール画面左側にある「クローラ」タブを開き、「クローラの追加」をクリックします。
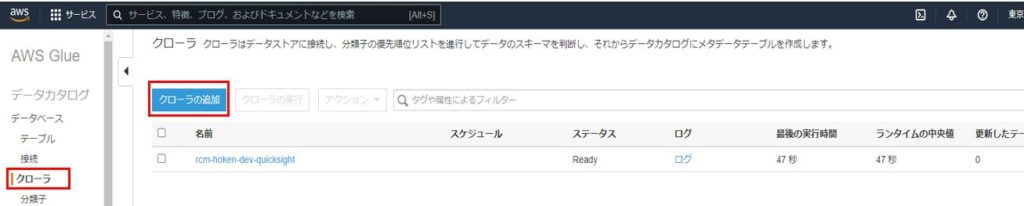
クローラ追加の画面に遷移し、クローラに関する情報を入力していきます。
まず初めに、クローラの名前を入力します。
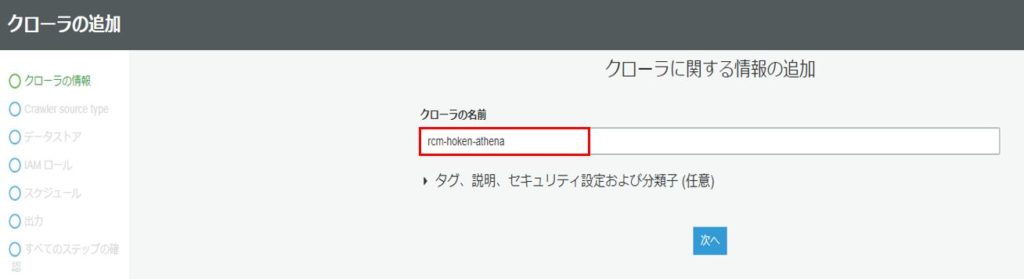
ソースタイプを選択します。今回はS3からクロールするため、ソースタイプは「Data stores」を選択します。
「Repeat crawls of S3 data stores」はS3からクロールする際に、全て再クロールするか、差分だけ再クロールするかなどを選択できます。今回は、全て再クロールする「Crawl all folders」を選択します。
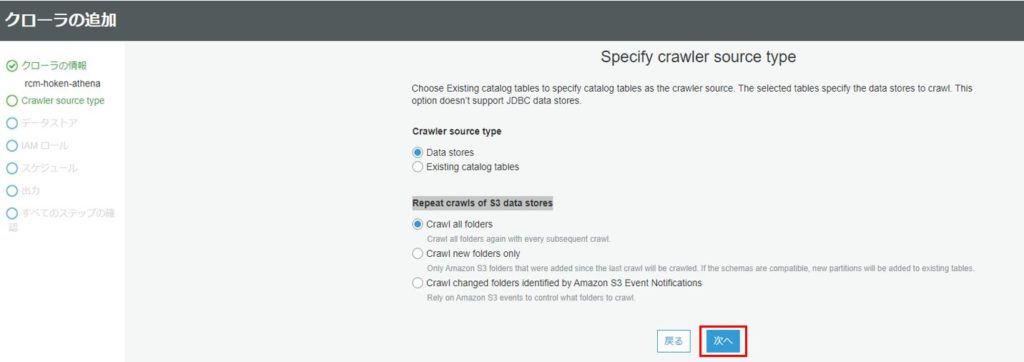
続いてデータストアの追加を行います。
データストアの選択では、今回クロールするサービスであるS3を選択します。
インクルードパスには、クロールするファイルがあるフォルダを指定します。
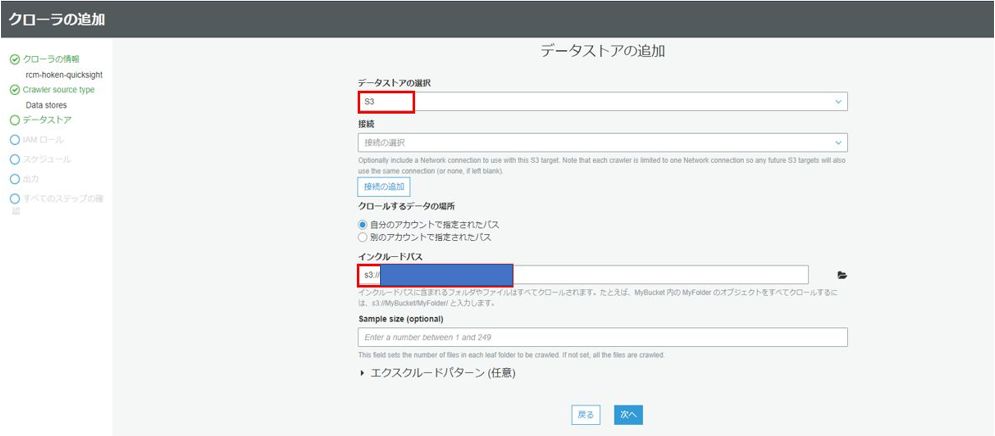
別のデータストアの追加の画面では、そのまま「次へ」をクリックします。
IAMロールの選択では、GlueやS3へのアクセス権限を持ったIAMロールを選択します。
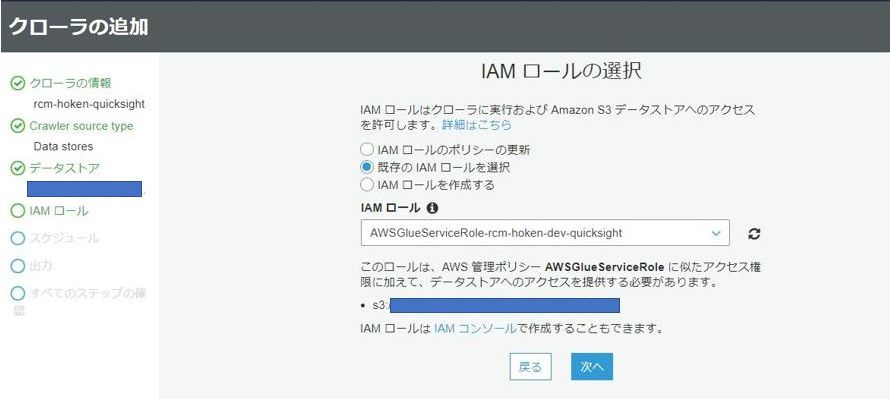
クローラのスケジュールを設定する画面では、手動で実行するという意味の「オンデマンドで実行」を選択したまま「次へ」をクリックします。
クローラの出力を設定する画面では、既に作成されているデータベースを選択するか、新規にデータベースを追加することが可能です。
今回は、新規に追加するため、「データベースの追加」をクリックします。
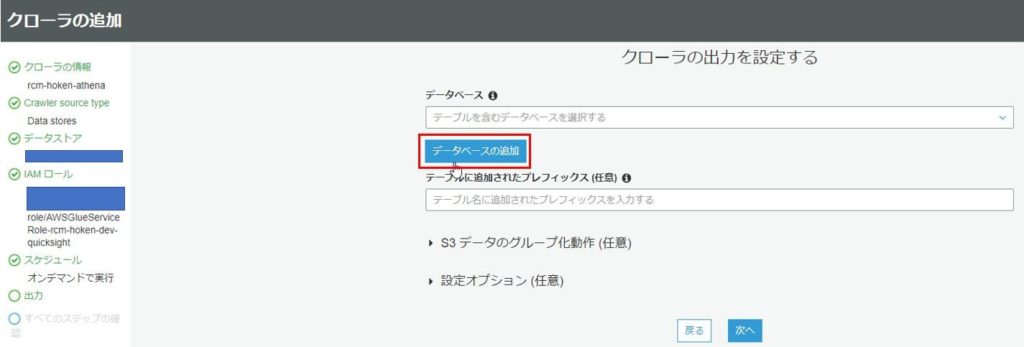
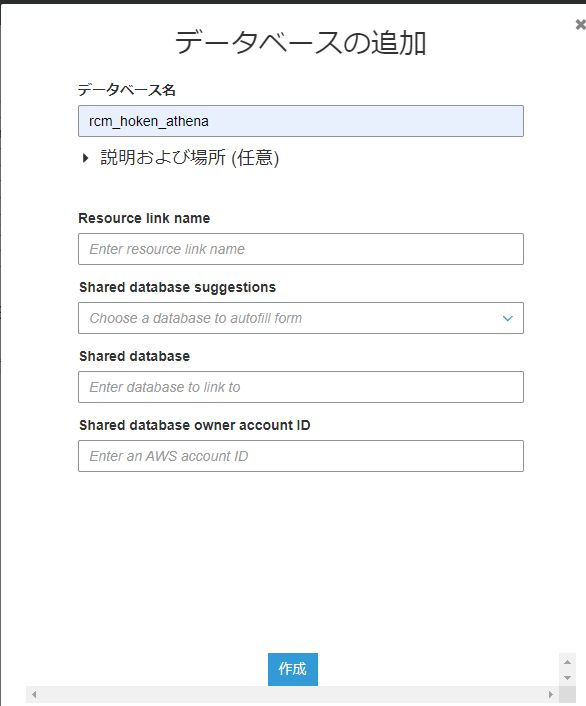
データベースの追加のポップアップが表示されたら、データベース名を入力して、「作成」をクリックします。
データベース名にはアンダースコア (_) を除く特殊文字はサポートされていないので、ハイフンなどは使用できません。(テーブル名も同様)
クローラの設定に問題が無ければ、「完了」をクリックします。
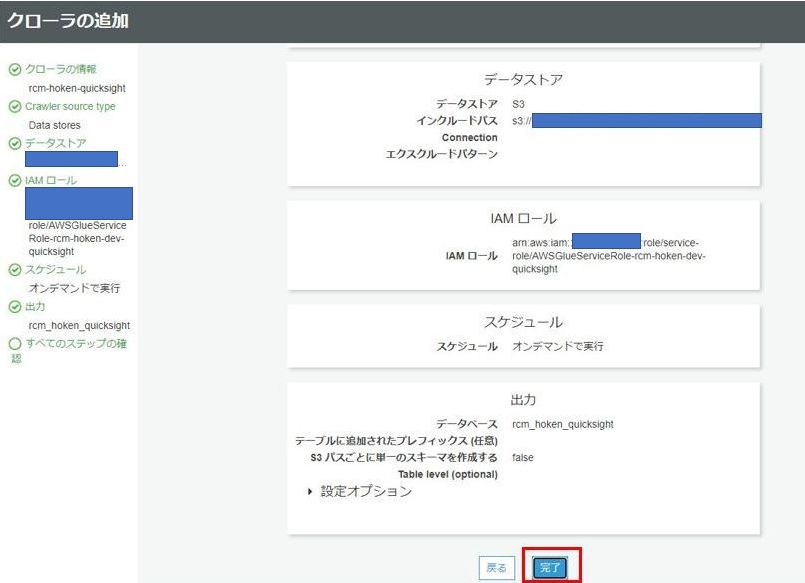
以上でクローラの作成は完了です!
クローラの実行
先ほど作成したクローラを実行して、テーブルを作成します。
Glueコンソール画面のクローラタブにある、先ほど作成したクローラを選択し、「クローラの実行」をクリックします。

ステータスが「Ready」になったら、「テーブル」タブをクリックし、テーブルが作成されていることを確認します。
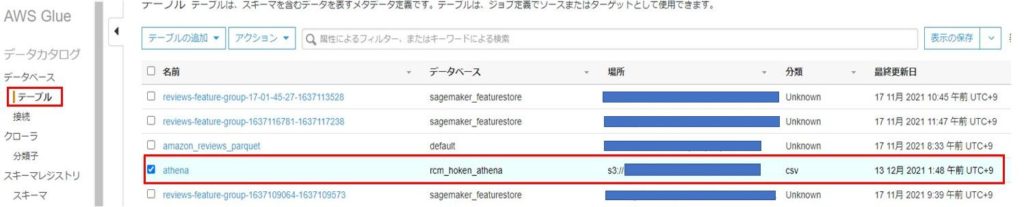
Athenaの構築
ここからは、Athenaの画面で操作をしていきます。
クエリを実行する際には、Athenaのコンソール画面から「クエリエディタを詳しく確認する」をクリックし、クエリエディタを開きます。
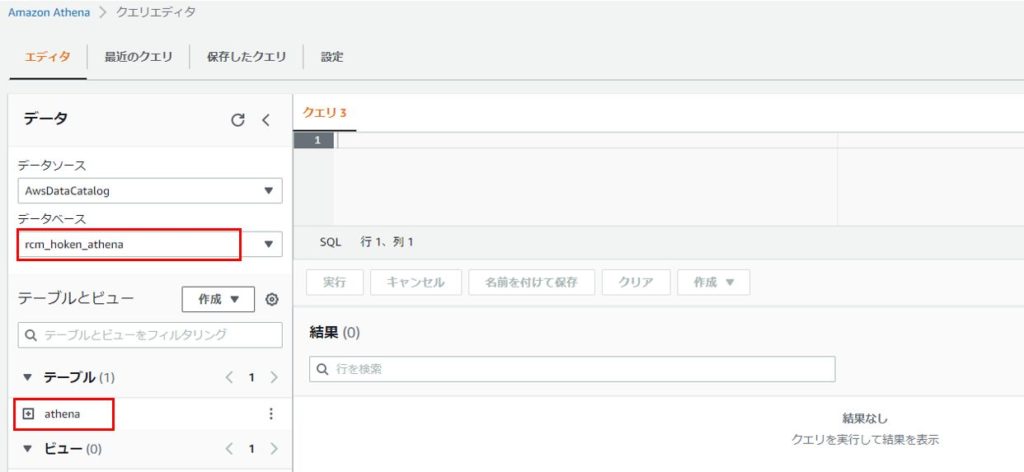
Glueで作成したデータベースを選択すると、テーブルが表示されます。
Glueの画面でクローラを実行し、テーブルを作成すると、Athenaの画面にも自動的に表示されるようになります。
クエリを実行する
実際にクエリを実行してみます。
select文を実行して、テーブルにある全てのデータを抽出します。
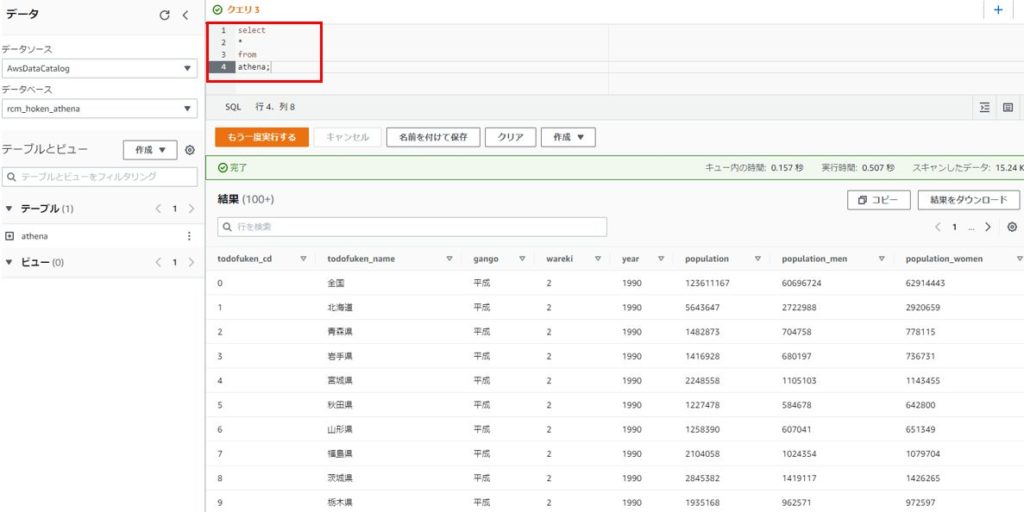
結果として、S3に置いたファイルのデータが出力されていることが確認できます。
QuickSightに連携
AthenaのデータをQuickSightに連携し、可視化するために、データセットを作成します。
QuickSightの画面左側にある「データセット」タブを開き、「新しいデータセット」をクリックします。
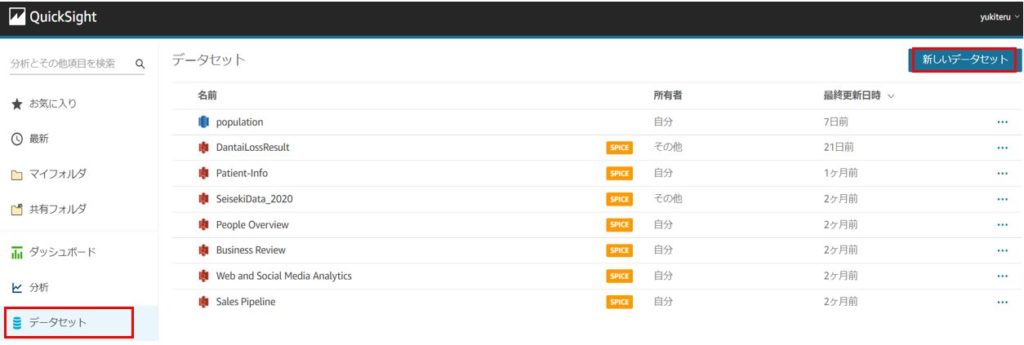
データセット作成の画面で「Athena」を選択します。
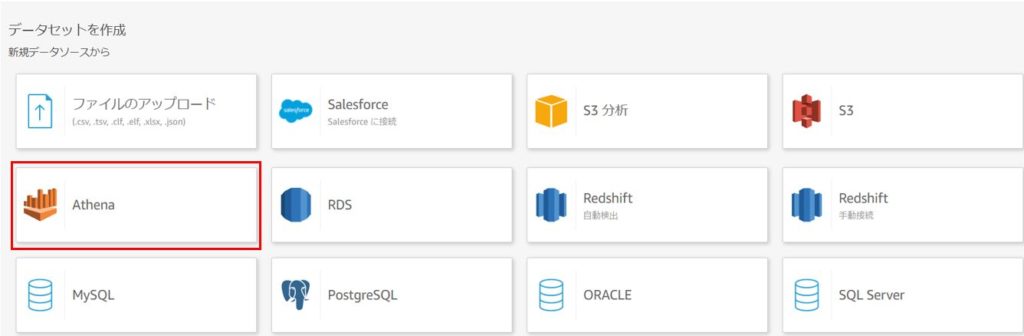
新規データソースを作成するポップアップ画面が表示されます。
データソース名を入力して、「データソースを作成」をクリックします。
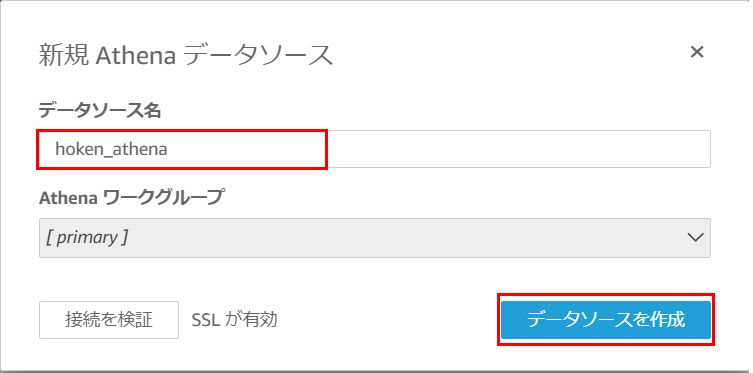
テーブルの選択画面で、今回作成したデータベースをテーブルを選択し、画面右下の「選択」をクリックします。
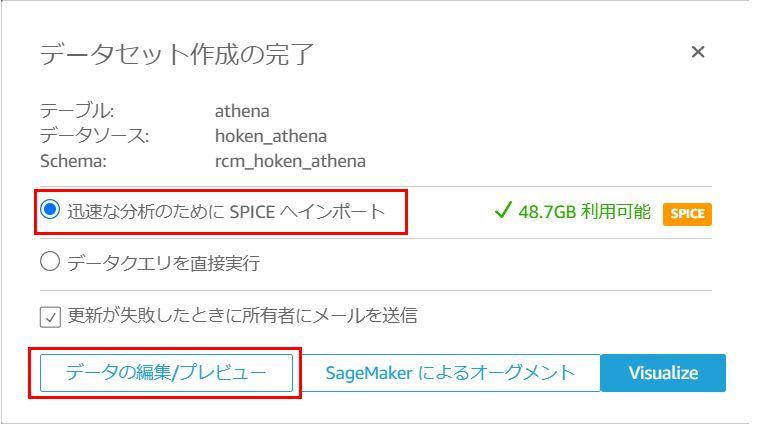
データセット作成の完了画面で、SPICEにインポートする方法か、直接クエリを実行する方法を選択できます。
今回はSPICEにインポートする方法を選択し、「データの編集/プレビュー」をクリックします。
次の画面で、項目やデータ型などの確認・編集が行えます。
特に問題が無ければ、「保存して公開」をクリックします。
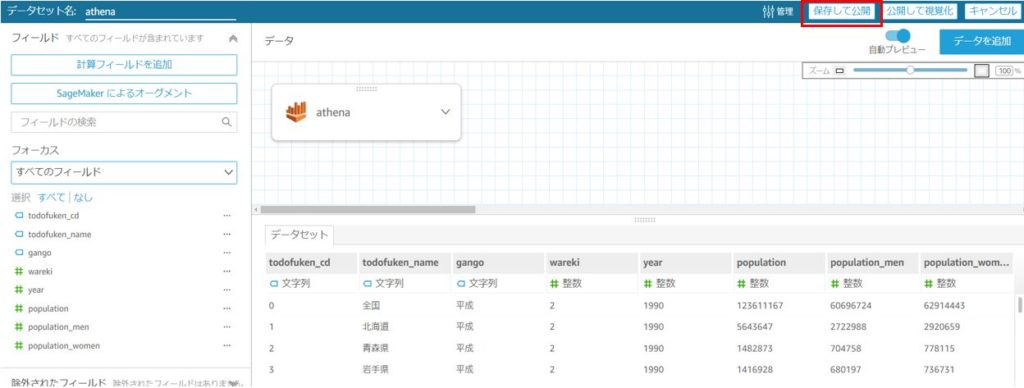
以上でデータセットの作成が完了しました。
続いて、データを可視化して分析を行っていきます。
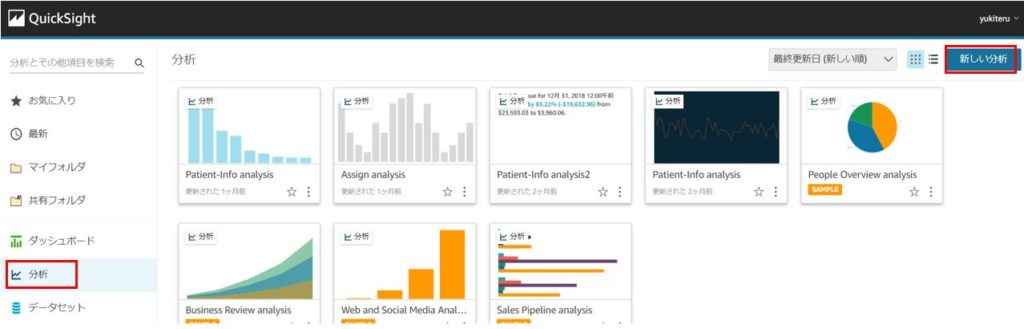
QuickSightの画面左側の「分析」タブを開き、「新しい分析」をクリックします。
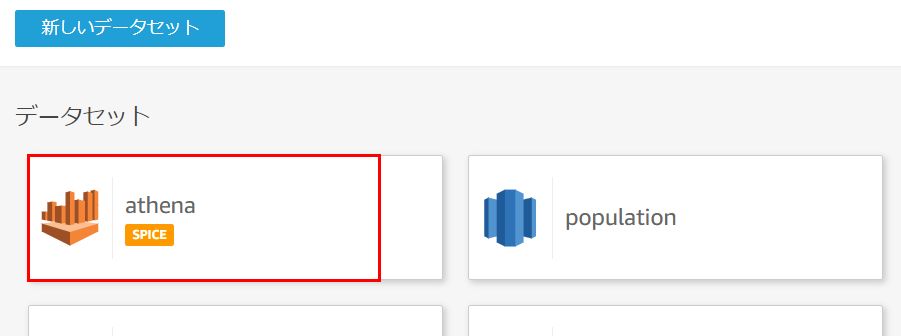
データセットの選択画面で、先ほど作成したデータセットを選択します。
表示されたダイアログ画面の、「分析の作成」をクリックします。
様々なグラフのビジュアルを指定して、分析を行うことができます。
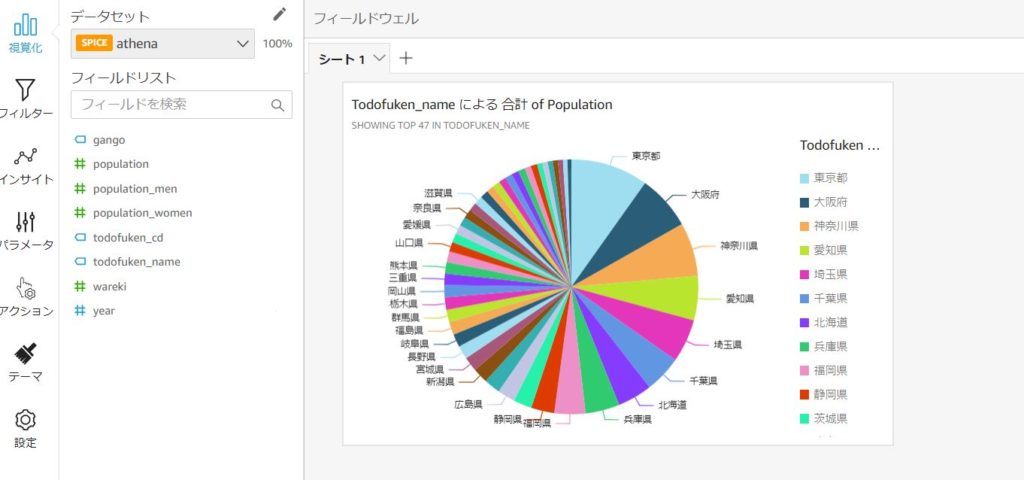
以上でAthenaとQuickSightの連携が完了しました!
さいごに
AthenaとGlueを使用してS3のデータに対してクエリを実行する方法と、AthenaとQuickSightの連携方法を紹介しました。
今回は、CSV形式のファイルを使用しましたが、JSON形式などのファイルに対してもクエリを実行することが可能です。
また、AWSでデータ分析をするサービスは、Athenaの他にRedshiftなどがあります。
次回は、Redshiftの構築やQuickSightとの連携を試してみたいと思います!